


Finding A Signal Amid Crypto News - Aludra June 24 Newsletter
Crypto media is overwhelming, but is any of it valuable?


Welcome back to the Aludra newsletter - thanks for being with us. As we’ve lamented often, there is a wide range of quality in reporting on the crypto space. The field is louder and more chaotic than many other asset classes despite its small size. But does this 24/7 onslaught of news, opinions, and coverage impact markets? Does a positive Bitcoin article on the Financial Times actually impact prices?
In this weeks article we look to answer this simple question: do articles and publications have an effect on crypto-asset markets and if so how can an investor use that knowledge to their advantage? We will walkthrough how we built a “proof-of-concept” experiment using TF-IDF, or Term Frequency Inverse Document Frequency, to analyze articles and try to derive some insight from them as they relate to market prices, in particular Bitcoin.
Main Analysis: Finding A Signal Amid Crypto News
Date Written: June 24, 2020
Disclaimer: This newsletter and article is in no way intended to provide financial advice or a recommendation of investment in any technology, virtual currency, cryptocurrency, or any financial asset. This article is for educational and informational purposes only.
In todays markets, news and media are a driving catalyst for price movement. For example, just this week on Monday June 22, White House trade official Peter Navarro said the China trade deal is "over" in an interview on Fox News. S&P 500 futures dropped 1.3% - until later that evening President Trump tweeted a ‘correction’ that the deal was still on:

As this was big news, major media outlets picked up the story:
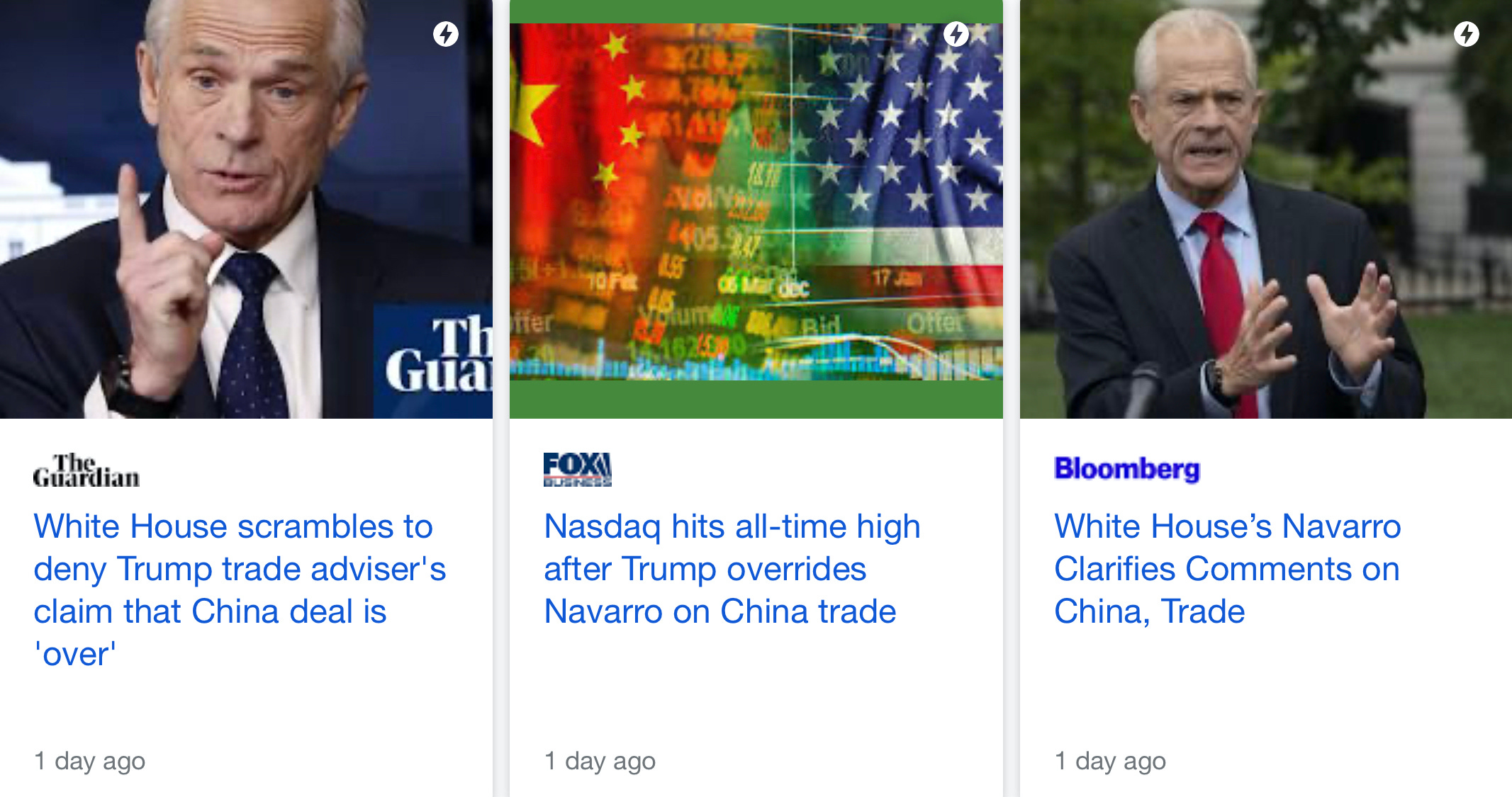
Source: Google
And the result? S&P500 futures rebounded 1.4%, closing the next day at 26,156.10, up 131.14 points or 0.5%. The Nasdaq hit an all-time high. A widely reported correction contributed to a notable rise in the markets.
The Hypothesis
Clearly, text-based information can be a powerful market catalyst, but in this example it’s obvious having a singular, authoritative voice like Trump in control of the narrative to clarify is beneficial.
For digital assets like Bitcoin, that type of central figure doesn’t exist. As a decentralized asset, Bitcoin has no CEO, President, or Chairman of its monetary policy to comment on recent developments or market performance. Since cryptocurrencies are a new asset class lacking traditional market catalysts such as earnings reports or press releases, news articles are one of the primary methods by which investors in the space form an opinion. And with opinion, comes action - buying and selling, based on conviction. And since there is no Bitcoin CEO to make declarative statements, many online articles on the subject are also opinion-based.
What you end up with is opinions driving other opinions, impacting markets and, to an extent, market performance - akin to eating your own dog food.
If we believe crypto articles can impact markets similar to reports about trade deals or company earnings reports, could (or should) an investor rely on news articles as a leading indicator for future prices? In essence, can we synthesize filet mignon out of Alpo? We set out to discover if we can learn from the past to derive such a trading strategy.
The Experiment
For our experiment, we built a text classification model that analyzed Bitcoin-focused articles over a 3 month time span in 2019 (2019-06-01 to 2019-09-01). The model essentially determines from the words in the article(s) the sentiment of the piece. If the sentiment was positive, we would expect, and tested for in our experiment, an increase in BTC/USD prices with a latent delay of about 24 hours (for the article to ‘make the rounds’ online). If the sentiment was negative, we would expect the opposite.
We chose this time period because it was a fairly volatile 3 months in that BTC/USD rose from ~$8600 to a high of ~$13,800 before returning back to ~$9500:

Source: CoinMarketCap
To be clear, this is a ‘proof-of-concept’ experiment. POCs such as this are beneficial because they are fast to design and test and provide the basis of whether or not a firm such as ours should spend the necessary time needed to productionalize the approach into a scalable solution. For transparency, at Aludra, we use a number of real-time data points as part of our trading, but not the exact approach outlined here.
Our experiment was built in 5 steps:
First, we collected the URLs of some articles from this time period - below are some examples:
Second, we developed a parsing tool to search through each URL and extract the text data.
Third, we preprocessed the data into a format that an algorithm could easily understand. For this, we started by using TF-IDF, or Term Frequency Inverse Document Frequency. TF-IDF is used by search engines to rank and weight search results to user queries. Similarly, in our case we used this algorithm to both encode each word in an article with a score that denotes not only how frequent the word is within a given article but also how frequently it appears over all article.
Fourth, we collected price data and calculated the price movements within a given day based on the open and close price. Once calculated, we mapped the price data from beginning to end of the encoded text data from the TF-IDF algorithm, and then associated each entry with a binary output (“positive price movement”, “negative price movement”).
Fifth and finally, we fit and trained a Random Forest model to classify a portion of this preprocessed data along with the associated output data, which we call our training data. Then we used the model to predict price movements on unseen data, our test data (articles), to see how well our model would perform out of sample.
The reasoning behind why we chose this approach using a Random Forest model is fairly simple - it is a transparent algorithm that allows us to understand “why” certain classification decisions were made at each step. The benefit to this is that when we want to understand why a decision is made, in the event that it is inaccurate, we can quickly diagnose the problem. This approach is different than many so-called “black box” models. While black box models at times might yield more accurate results, when we are making investment decisions we always seek to understand our models and processes top to bottom and end to end. This helps to limit and reduce model risk.
As trading strategy, the approach to use this model would be to use the binary output from the model (article in -> BTC/USD price forecast up/down for tomorrow) as a strategy in and of itself, or as an input to additional systems that we have created.
To recap, here is a quick overview of the pipeline we’ve created:
Problem Type: Classification
Range of Data: 2019-06-01 to 2019-09-01
Collection of URLs of Bitcoin-focused articles
Data loader function that iterates through urls and extracts relevant text from HTML pages (creates the dataset)
Preprocessor that cleanses and fits data utilizing a TFIDF model
Map price performance data to keywords
Random forest model that fits to training data and then predicts on unseen data
The Results
Our out of sample results were fairly accurate:
Accuracy: 50%
Precision: 78%
Recall: 70%
While the accuracy was around 50%, the precision of our model, or its ‘usefulness’ was quite high at 78%. To improve the performance of the model one could seek to include more data. One of the primary problems that we observed in conducting the experiment is that many of the URL we tried to get from this time period aren’t live anymore (an interesting observation on the state of crypto-journalism to say the least).
This also yields another conclusion - to make a truly effective model, one would need to store and collect their own data (both the inputs and the outputs), as we do with all of our production models. Ensuring the integrity of a dataset makes for a more robust and effective product. Finally, one should experiment with different parameters and also different preprocessing schemas for feature extraction from the text.
So would we use this to trade with?
In short, no. Crypto-markets are incredibly nuanced and can change quickly. Analying an article once a day might provide some leading indication of where the markets may go, but likely wouldn’t be fast enough as a true signal - hence our accuracy percentage.
While we do believe text data, namely articles and publications, can and do influence crypto-markets, there is a major consideration to ‘when’ they do - both the time of day and the calendar date. Trading strategies are all about timing and this style of trading wouldn’t fit in with ours. Despite this, we believe there are likely trading ‘bots’ actively scraping news articles, creating some sort of inference from the contents of the article, and using that as logic for trading. Is it for us, no, but maybe for others. Instead, as discussed, we would look to potentially use signals derived from this experimental model as part of a holistic trading system - one signal combined and weighed accordingly among dozens. We will continue the experiment on more recent articles to see how the model performs over a longer timeframe.
How can we make these newsletters more valuable to you? We’d love to hear your feedback. Connect with us by email.
If you found this newsletter interesting, please consider sharing it, thank you.
Disclaimer: This newsletter and article is in no way intended to provide financial advice or a recommendation of investment in any technology, virtual currency, cryptocurrency, or any financial asset. This article is for educational and informational purposes only.